── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::combine() masks gridExtra::combine()
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
✖ purrr::map() masks maps::map()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Code
library(ggplot2)library(scales)
Attaching package: 'scales'
The following object is masked from 'package:purrr':
discard
The following object is masked from 'package:readr':
col_factor
The following object is masked from 'package:viridis':
viridis_pal
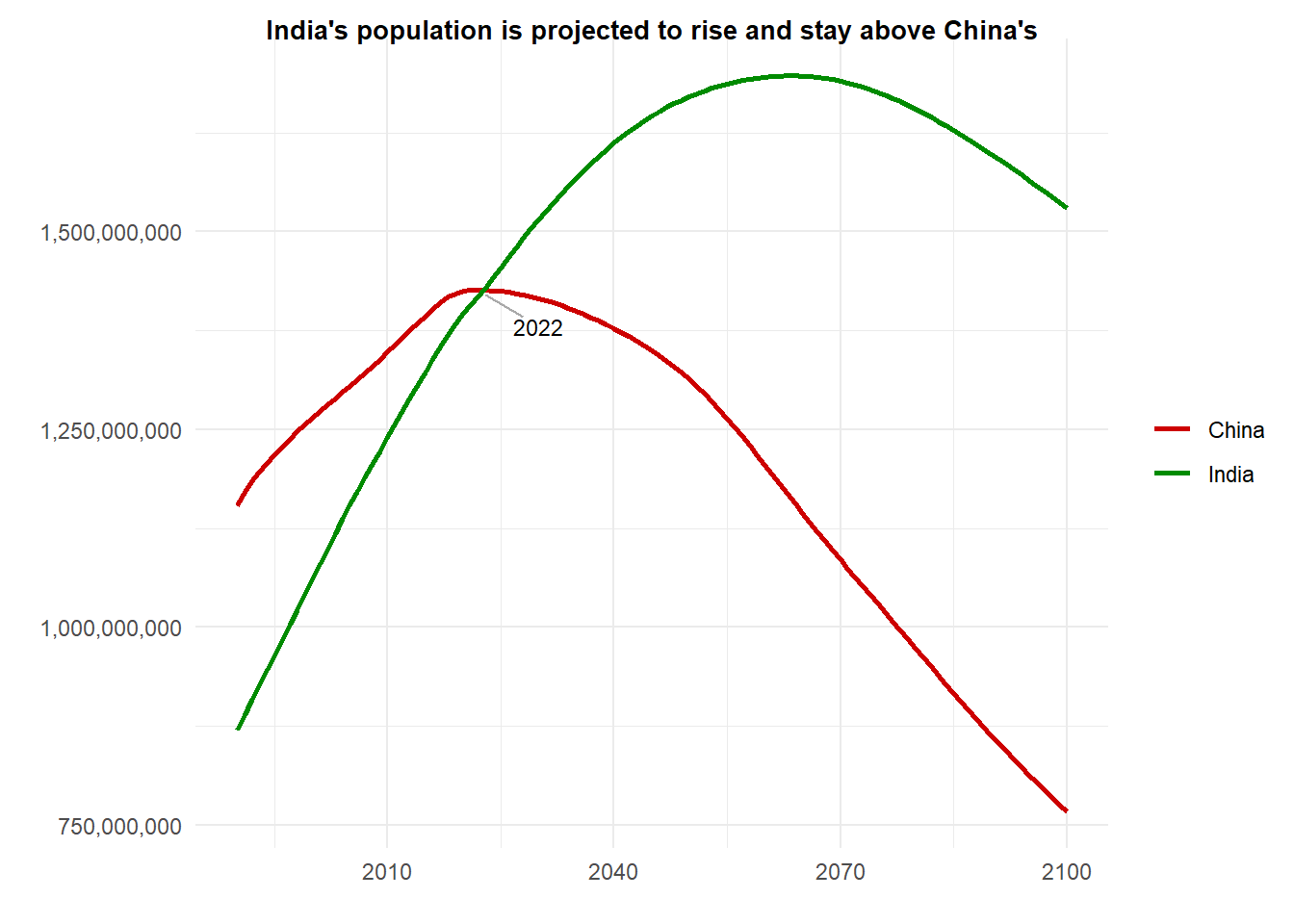
pop_proj <-read.csv("pop_projections_total.csv", header =TRUE, check.names =FALSE)pop_proj_age <-read.csv("pop_projections_byage.csv", header =TRUE, check.names =FALSE)pop_proj_plot <- pop_proj %>%ggplot() +geom_line(aes(x = Time, y = Value, color = Location), linewidth =1) +scale_color_manual(values = custom_colors) +#geom_point(data = data.frame(Time = 2023, Value = 1420000000), aes(Time, Value), color = "blue", size = 11, alpha = 0.3) +labs(x ="", y ="", title ="India's population is projected to rise and stay above China's") +scale_y_continuous(labels = scales::label_comma()) +kv_theme() +geom_segment(aes(x =2023, y =1420000000, xend =2028, yend =1392000000), color ="darkgrey") +annotate("text", x =2030, y =1380000000, label ="2022", color ="black", size =3) pop_proj_plot
One of the biggest points of discussion surrounding India’s potential growth trajectory over China is its population growth. We used United Nations data to observe the population outlook for our two countries of interest. First we note that India began to overtake China’s population in 2022, and is projected to clearly and consistently rise above China for at least 77 years. The population argument as it relates to economic growth essentially comes down to the idea that larger populations drive greater production and consumption, which in turn drives a larger economy. While this may be the case (and economic theory generally backs this up in the long run), there are other complexities that a larger population may introduce, such as more damaging environmental demands, which could possibly counteract some of the potential growth. We will explore this idea later in this section.
Code
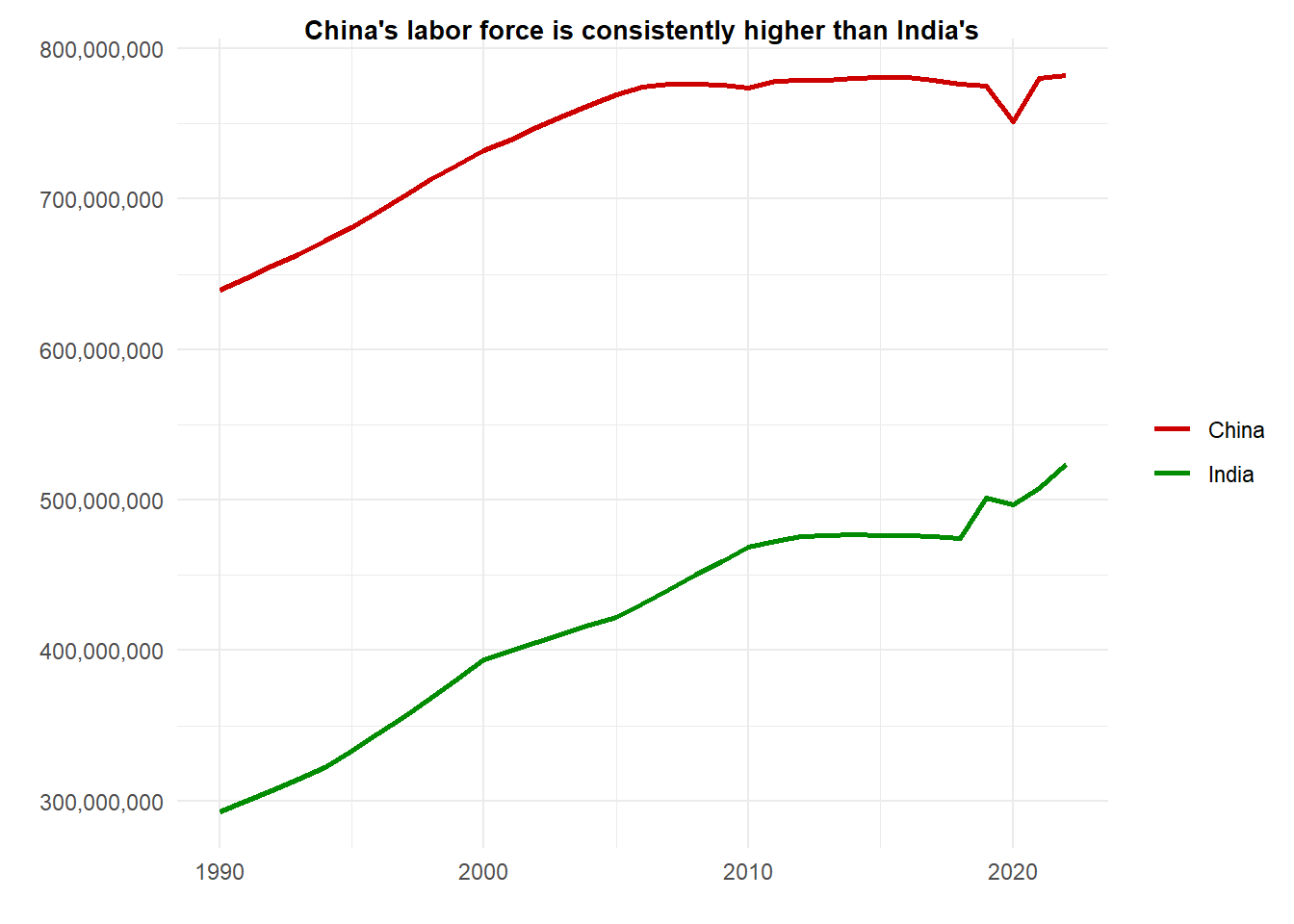
LF <-read.csv("LaborForce.csv", header =TRUE, check.names =FALSE)LF <-pivot_longer(LF, cols='1960':'2022', names_to ="year", values_to ="labor_force")LF$year <-as.integer(LF$year)LF_plot <- LF %>%filter(Country %in%c("India", "China") & year >=1990) %>%ggplot() +geom_line(aes(x = year, y = labor_force, color = Country), linewidth =1) +scale_color_manual(values = custom_colors) +#geom_point(data = data.frame(year = 2021, population = 1400000000), aes(year, population),# color = "black", size = 11, alpha = 0.3, shape = 1) +labs(x ="", y ="", title ="China's labor force is consistently higher than India's") +scale_y_continuous(labels = scales::label_comma()) +kv_theme() LF_plot
While India’s population is almost certain to outpace China’s, we wanted to look deeper into how this relates to their economies. To do so we examined how each country’s labor force has changed over time using data from the World Bank. A labor force is defined as people aged 15 and older who are either currently employed or actively looking for work (essentially the “willing and able” working population of a country). This reveals a stark result: China’s labor force is significantly higher than India’s, and has been so for the past three decades. Because of the size and persistence of the gap, the simple population argument is brought under scrutiny. While India’s population may grow much faster, it is unclear how this will translate into a population that is actively contributing to economic growth by working.
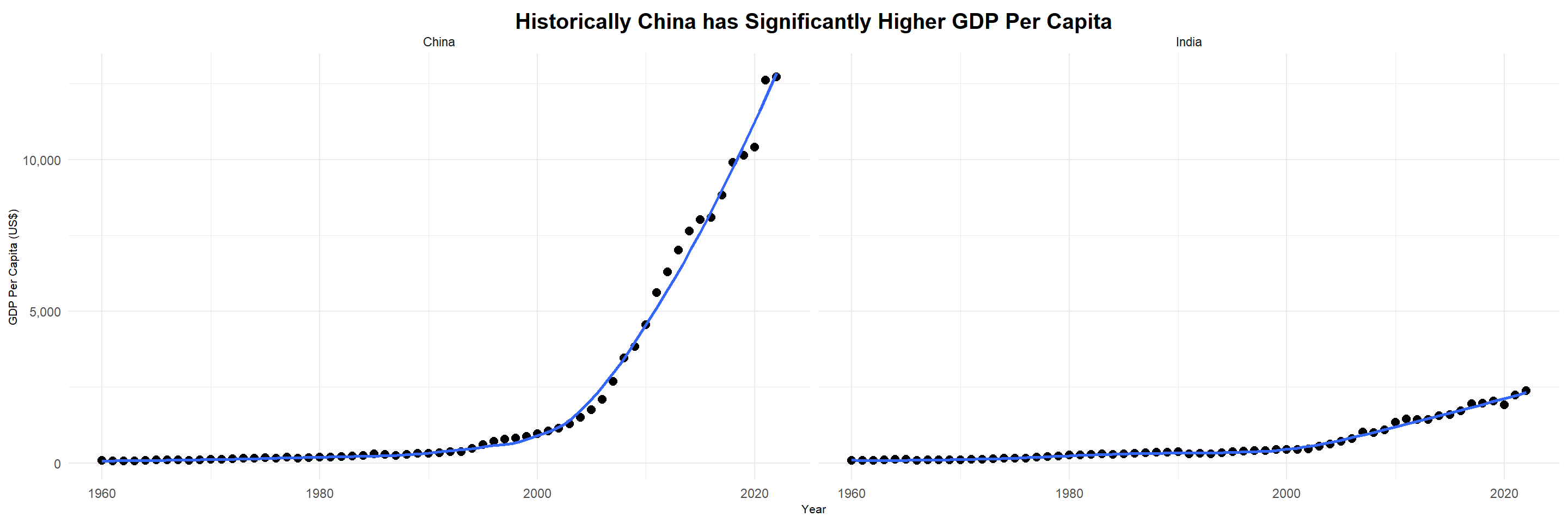
ggplot(GDP_vals, aes(year,`GDP per Cap`)) +geom_point(color ="Black", size =2.5) +stat_smooth(method ="loess", se =FALSE, span =0.5)+facet_wrap(Country~.)+ylab("GDP Per Capita (US$)")+xlab("Year")+ggtitle("Historically China has Significantly Higher GDP Per Capita")+scale_y_continuous(labels = scales::label_comma()) +kv_theme() +theme(plot.title =element_text(hjust =0.5, size =15))
`geom_smooth()` using formula = 'y ~ x'
Next we consider China and India’s economic sizes by examining Gross domestic product (GDP) per capita. This is a metric that describes a country’s economic output per person, so a high value indicates a stronger economy. GDP per capita is also a better measure for comparing overall economy than nominal GDP because it takes into account population size, which is especially important for China and India because they are the two most populous countries in the world. From this scatterplot with a fitted line, we see that while both China and India have had growing GDP per capita levels since 1960, since the year 2000 China’s GDP per capita has skyrocketed compared to India’s. As of 2020, the difference between their GDP per Capita is over $10000. When looking at GDP growth without considering other factors, it appears that if current trends continue, it will take many years for India’s GDP per Capita to surpass China’s. Both countries seem to be at an upward trajectory, but it remains to be seen if China’s growth will stagnate while India continues their increasing trend of GDP per capita growth.
Code
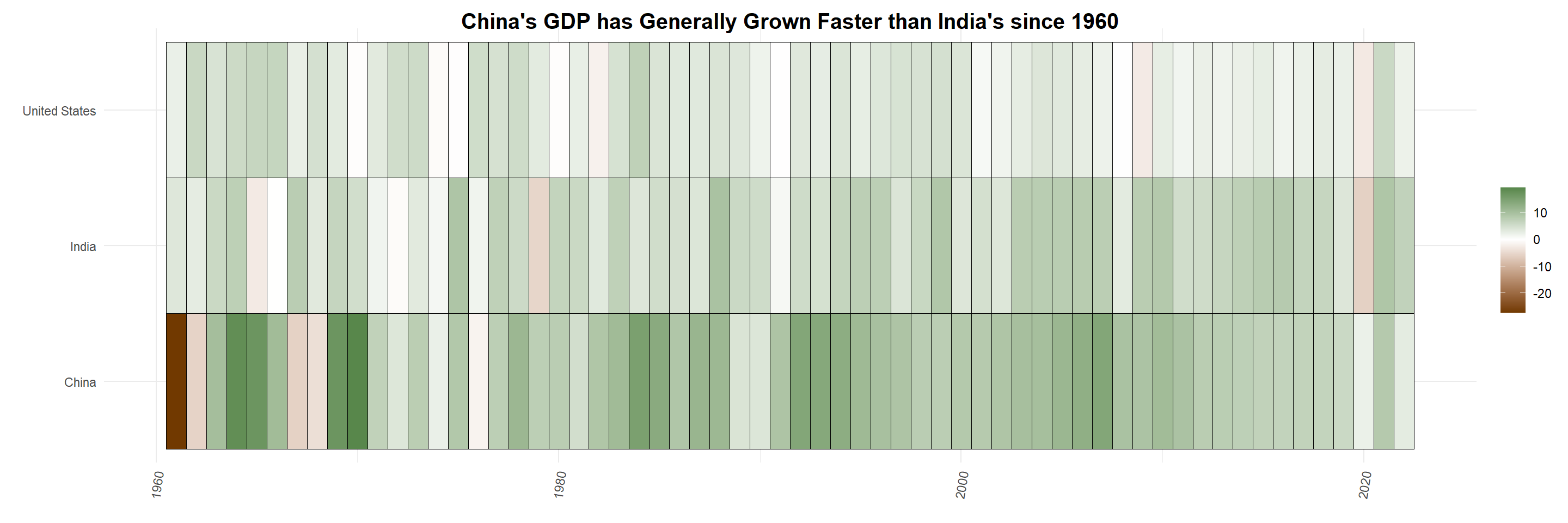
ggplot(GDP_growth, aes(year,Country, fill =`GDP Growth %`)) +geom_tile(color ="Black") +kv_theme() +theme(axis.text.x =element_text(angle =80, vjust=0.5))+ggtitle("China's GDP has Generally Grown Faster than India's since 1960")+scale_fill_gradient2(low =muted("orange"),mid ="white",high =muted("green"),midpoint =0 )+labs(x ="", y ="") +theme(plot.title =element_text(hjust =0.5, size =15))
We use the United States’ GDP growth as a benchmark for comparison because it is considered the largest economy in the world (it has the highest nominal GDP out of any country). When comparing China and India’s GDP growth percentage, we see that both countries have a general trend of increasing GDP growth, but from the darker spots on the plot we can see that in the early 2000’s China had been growing faster. However, post 2010, India’s GDP growth percentage has been increasing more than both China and the US; there is an exception for the year 2019 where both India and the United States had a decrease in GDP growth and China’s was stagnant. This is also the year that COVID-19 pandemic emerged, so it makes sense that GDP growth was negative for most of the world, including even the strongest economies. Despite the emergence of COVID and its negative impact on economies over the world, both China and India managed to recover and even regain their upward trends in 2020 and 2021. Hence, both China and India display the characteristics of strong economies that are resilient to sudden recessions or unforeseeable changes to the society.
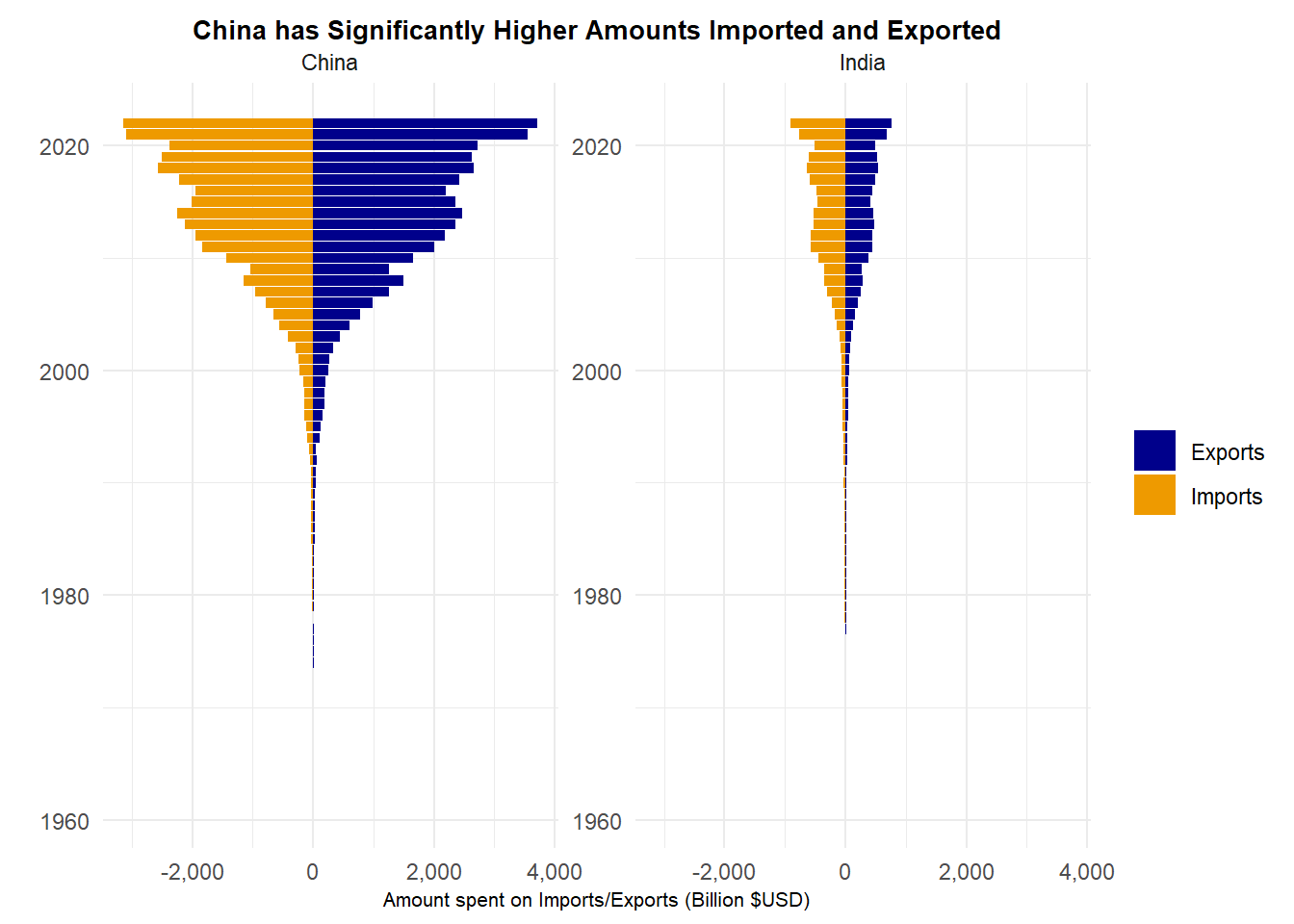
ggplot(pivotimportexports,aes(x=year,y=value,fill=type))+geom_bar(stat="identity")+xlab("year")+ylab("Amount spent on Imports/Exports (Billion $USD)")+facet_wrap(Country~.,scales="free_y")+coord_flip()+scale_fill_manual(values =c("blue4", "orange2"))+theme(axis.text.x =element_text(angle =80, vjust=0.5))+ggtitle("China has Significantly Higher Amounts Imported and Exported")+labs(x ="") +scale_y_continuous(labels = scales::label_comma()) +kv_theme()
In the previous plots, we have seen that China’s economy has grown much faster that India’s– in this plot we get a glimpse as to why. Exporting goods brings profits to a country which stimulates economic growth because they produce the goods for a lower price than they sell them for; countries import goods that they are unable to produce themselves. Thus, it is generally desirable for countries to have a positive trade balance (i.e. greater exports for profit than imports). First, China exports many more goods and services than India does. From the plot we see that since the year 2006, China has exported over 1 trillion US dollars worth of goods and has reached about 3.7 trillion $USD in 2022. Meanwhile India has also exported many billions of US dollars worth of goods, but not to the amount that China has, and from the plot we see that ever since the year 2000 India imports more goods than they export. Thus, it makes sense that India’s rate of GDP growth has historically been less than China’s.
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
Code
yoyc_India <- yoy_comp %>%filter(year >=2016& Country =="India") %>%ggplot() +geom_col(aes(x = year, y = value, fill = indicator), position ="dodge", width = .9) +scale_fill_brewer(palette ="Greens", direction =-1) +geom_vline(xintercept =c(2016.5, 2017.5, 2018.5, 2019.5, 2020.5, 2021.5), color ="grey", size =0.5) +geom_hline(yintercept =0, size =0.4) +scale_x_continuous(breaks =c(2016, 2017, 2018, 2019, 2020, 2021, 2022)) +kv_theme() +labs(x ="", y ="(%)", title ="India") +theme(plot.title =element_text(margin =margin(b =12)))grid.arrange(yoyc_China, yoyc_India, top ="Year over year changes in key economic indicators")
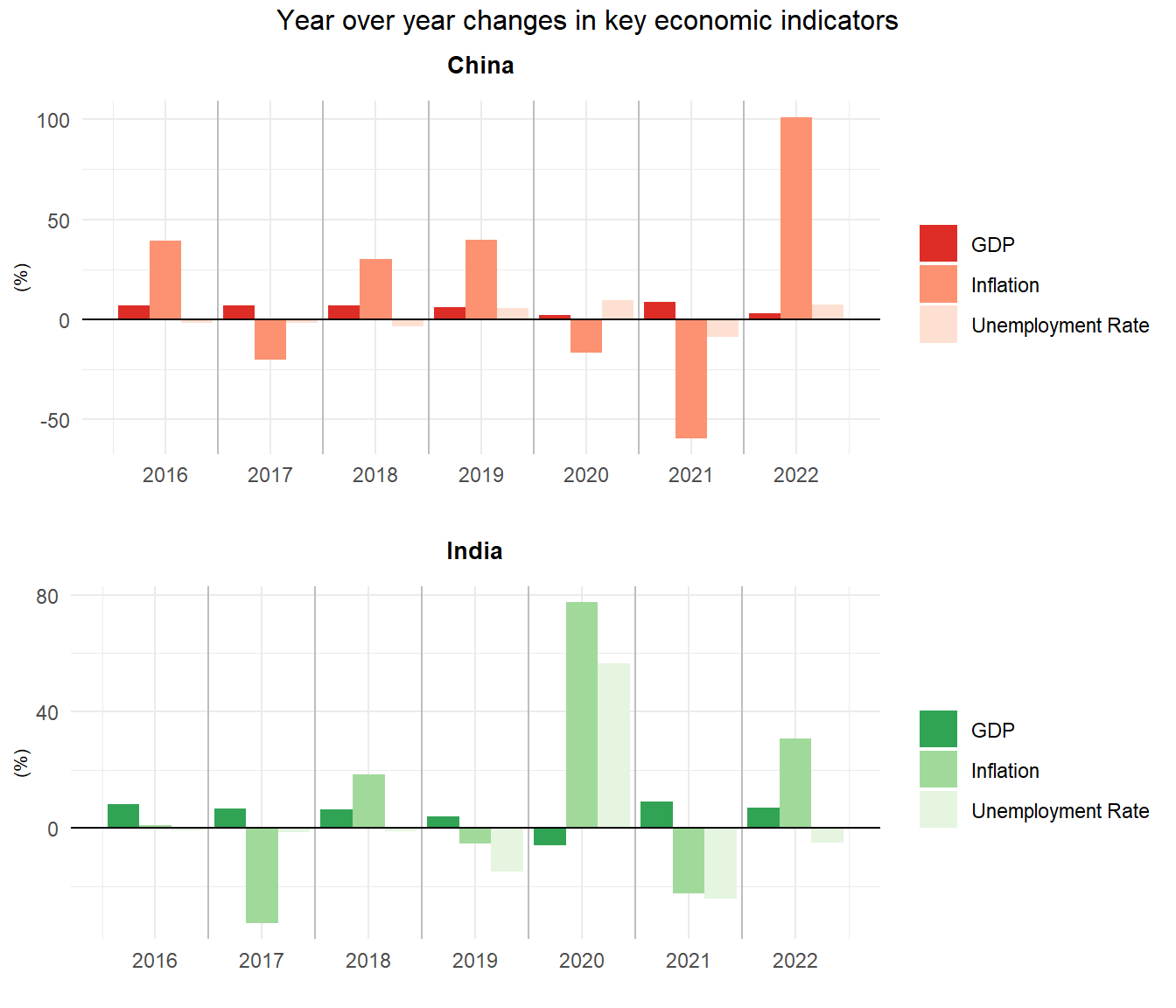
While GDP provides a representative and accurate conception of an economy in the big picture, we wanted to explore additional factors that are relevant to economic health and growth. We transformed data from the World Bank to obtain the year-to-year change in GDP, inflation, and unemployment rate of both countries. A country’s unemployment rate simply reflects the proportion of the labor force that cannot find work, and inflation reflects an overall change in prices across an economy over a period of time (annually here). The result of positive inflation (price increases) is a decrease in purchasing power, where each unit of currency buys fewer goods and services.In the plot above, a bar growing below 0 can generally be viewed as a positive outcome for inflation and unemployment1, as it indicates that prices have decreased or more people are able to find work (and therefore earn income to purchase goods/services) relative to the previous year. On the other hand, a bar growing above 0 can be viewed as a positive outcome for GDP, as it signifies that the country’s economic output has grown since the previous year. In this hypothetical scope, if we saw inflation and unemployment growing downward, while GDP grew upward, the country would be experiencing the “maximum positive” outcome (i.e. low prices, higher consumption, greater output)2.
We first observe from the plot that all three indicators do not always change in the strictly “maximizing” or “minimizing” way. Instead, these factors seem to mitigate each other, and prevent unconstrained growth/collapse. For example, in years where GDP rises, inflation growth mitigates the overall economic growth (e.g. 2018 for China and India). We also observe that inflation seems to have the greatest fluctuation year-to-year relative to the other indicators. This suggests that a more detailed look into prices and purchasing power may tell a different story of how individuals fare in each country’s economy compared the the overall macroeconomic picture. For instance for the most recent data available (2022), China’s inflation rate has grown nearly 100% while India’s has grown only around 35%. Additionally, India has experienced a decrease in unemployment whereas China faced the opposite in the same year. This suggests that though both countries experienced GDP growth, perhaps the microeconomic landscape of India or China will account for the overall growth differential in the years to come.
3.0.3 Environmental tradeoffs and impacts
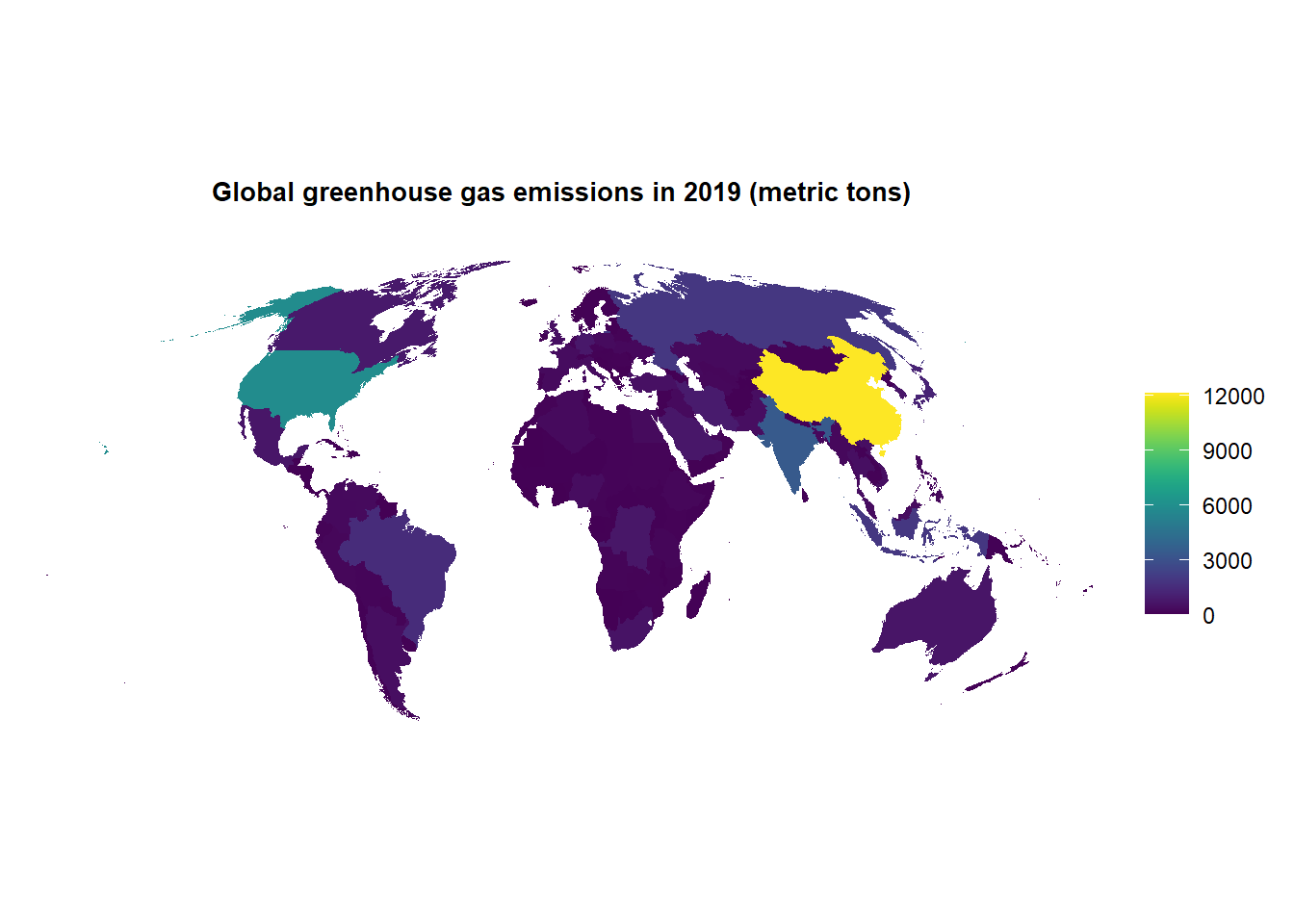
Given the emerging environmental crisis of the world, it is perhaps irrelevant to discuss economic growth in the long-run without considering a country’s resilience to climate-related disasters. This is particularly the case when China and India rank high in the world order of total greenhouse gas (GHG) emissions. As we can see in the map below, China is the top contributor to global emissions, and India trails behind the US as the third highest. Environmental impacts can cause significant shock to a country’s economy (e.g. decreased access to fuel/electricity due to resource depletion or productivity loss due to physical landscape damage).
ghg$Country <-as.factor(ghg$Country)ghg <-pivot_longer(ghg, cols='2020':'1990', names_to ="year", values_to ="emissions")world <-map_data("world") %>%filter(! long >180)world <- world %>%rename(Country = region) %>%mutate(Country =factor(Country))diff <-setdiff(world$Country, ghg$Country)world <- world %>%mutate(Country =recode(str_trim(Country),"USA"="United States", "UK"="United Kingdom","Turkey"="Türkiye", "Trinidad"="Trinidad and Tobago"))ghg_2019 <- ghg %>%filter(year ==2019)world_ghg <-inner_join(world, ghg_2019, by ="Country")global_emit <-ggplot(data = world_ghg, mapping =aes(x = long, y = lat, group = group)) +coord_fixed(1.3) +geom_polygon(aes(fill = emissions)) +scale_fill_viridis() +ggtitle("Global greenhouse gas emissions in 2019 (metric tons)") +kv_theme() +theme(axis.text =element_blank(),axis.line =element_blank(),axis.ticks =element_blank(),panel.border =element_blank(),panel.grid =element_blank(),axis.title =element_blank(),plot.title =element_text(margin =margin(b =20))) +coord_map("moll")
Coordinate system already present. Adding new coordinate system, which will
replace the existing one.
Code
global_emit
Code
gain <-read.csv("gain.csv", header =TRUE, check.names =FALSE)gain <-pivot_longer(gain,cols='1995':'2021', names_to ="year", values_to ="score")gain_21 <- gain %>%filter(year >=1995) %>%na.omit()quantiles <-quantile(gain_21$score, probs =c(0, 1/3, 2/3, 1))gain_21$score_cat <-cut(gain_21$score,breaks = quantiles,labels =c("Low", "Medium", "High"))G20 <-c("Argentina", "Australia", "Brazil", "Canada", "China", "France", "Germany", "India","Indonesia", "Italy", "Japan", "South Korea", "Mexico", "Russia", "Saudi Arabia","South Africa", "Türkiye", "United Kingdom", "United States", "European Union (27)")gain_21$year <-as.numeric(gain_21$year)gain_21 %>%filter(Name %in% G20) %>%ggplot(aes(year, Name, fill = score_cat)) +geom_tile(alpha =0.95) +kv_theme() +scale_fill_manual(values=c('#ffffd4','#fe9929','#993404')) +scale_x_continuous(breaks =seq(min(gain_21$year), max(gain_21$year), by =2)) +labs(x ="", y ="", title ="ND-Gain index scores over time - G20 countries") +theme(plot.title =element_text(margin =margin(b =10)))
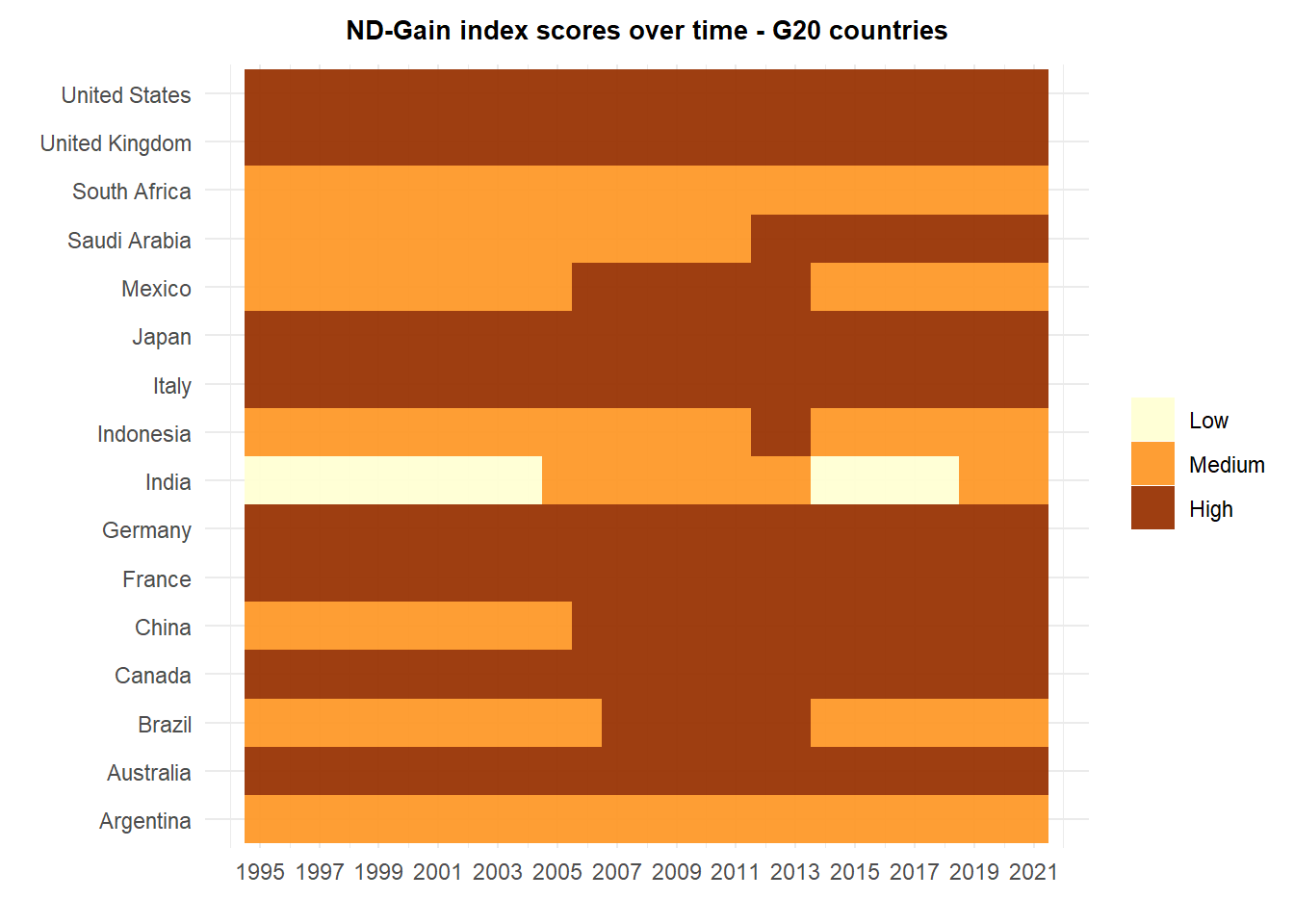
To unpack China and India’s vulnerability to climate change, we transformed data on the ND-GAIN index assigning a score of low, medium, and high based on where a country fell between or outside of the 1st and 3rd quartiles of scores in a given year. We chose to compare India and China’s scores to other G20 countries over time since the group’s (in which China and India are members) mission is to coordinate on key issues relating to economic stability and sustainable development. As we can see in the plot, China transitioned to a high score in 2006, signifying a greater resilience to climate change impacts, on par with key world players like Japan and Germany. On the other hand, India is the only G20 country that has experienced a low score in the past 28 years (when the index was first constructed), though it has transitioned back to a medium score. The ND-GAIN score captures a country’s exposure/sensitivity to environmental shocks, as well as the capacity to adapt through measures like good governance, economic strength, and more. Therefore we cannot precisely attribute the scores of India and China to one area, but we will explore this further.
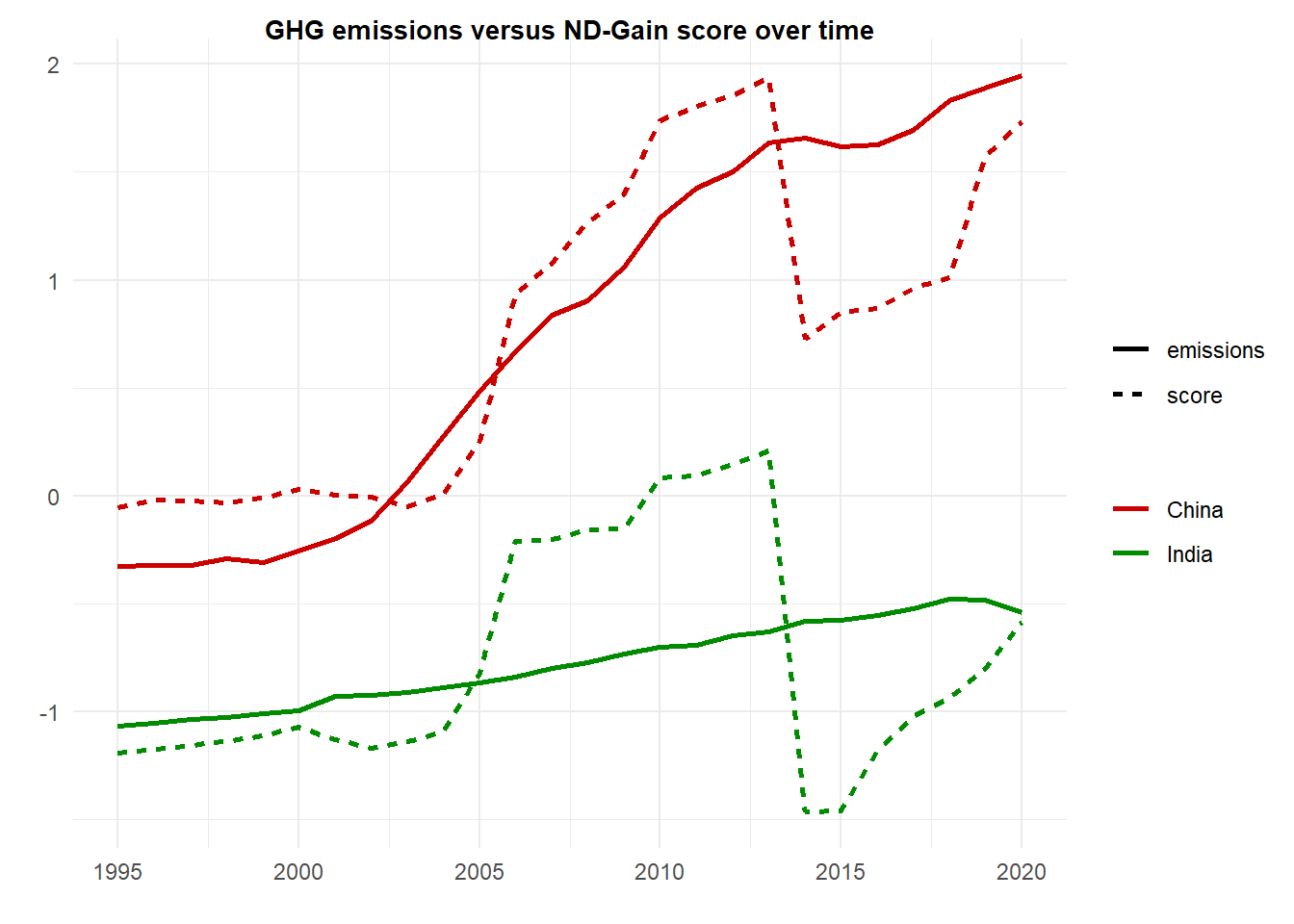
For instance, we wanted to investigate whether a change in ND-GAIN score could be related to a change in emissions from year to year. To do so we standardized time series data on both aspects so we could observe their changes in conjunction. On a base level, we see again that both China’s emissions and score have consistently been higher than India’s since 1995. In addition, the rate of China’s increasing emissions is much steeper than India’s. This indicates that perhaps China has more robust measures in place to deal with the outcome of its higher pollution, which contributes to its higher resilience score. We also notice that there are greater fluctuations in the ND-GAIN score over time relative to emissions quantities (particularly in the face of sharp changes like in 2014). Again, this suggests that the impact of heightened emissions does not influence the GAIN score in real time (i.e. its impacts may be felt later, while the score is more reflective of other resilience measures in the short run).
Code
# units of (quad Btu)chinaenergy =read.csv("chinaenergy.csv")indiaenergy =read.csv("indiaenergy.csv")energy =rbind(chinaenergy,indiaenergy)energy =pivot_longer(energy,cols='X1980':'X2021', names_to ="Year", values_to ="Total Production")energy =pivot_wider(energy, names_from = Type,values_from =`Total Production`)energy = energy %>%mutate(coal = Coal/Production)%>%mutate(`natural gas`=`Natural Gas`/Production)%>%mutate(petroleum =`Petroleum and other liquids`/Production)%>%mutate(clean =`Nuclear, renewables, and other`/Production)energy$Year<-gsub("X","",as.character(energy$Year))energy$Year <-as.integer(energy$Year)energy =pivot_longer(energy,cols='coal':'clean', names_to ="Energy Usage Proportions", values_to ="Percentages")energyrecent = energy[energy$Year >=2010,]energyrecent$`Energy Usage Proportions`=as.factor(energyrecent$`Energy Usage Proportions`)`Fuel Type`=factor(energyrecent$`Energy Usage Proportions`, levels =c("coal","natural gas","petroleum","clean"))
Code
colors =c("darkred","yellow3","tan","green3")ggplot(energyrecent, aes(x =`Country`, y= Percentages, fill =`Fuel Type`)) +geom_bar(position="fill", stat="identity", width =0.6)+facet_wrap(~Year, scale="free_x")+scale_fill_manual(values = colors) +kv_theme() +#theme(legend.position = "bottom")+theme(axis.text.x =element_text(angle =80, vjust=0.5))+ggtitle("Renewable Energy Usage has not Significantly Increased for Either Country")+labs(x ="", y ="")
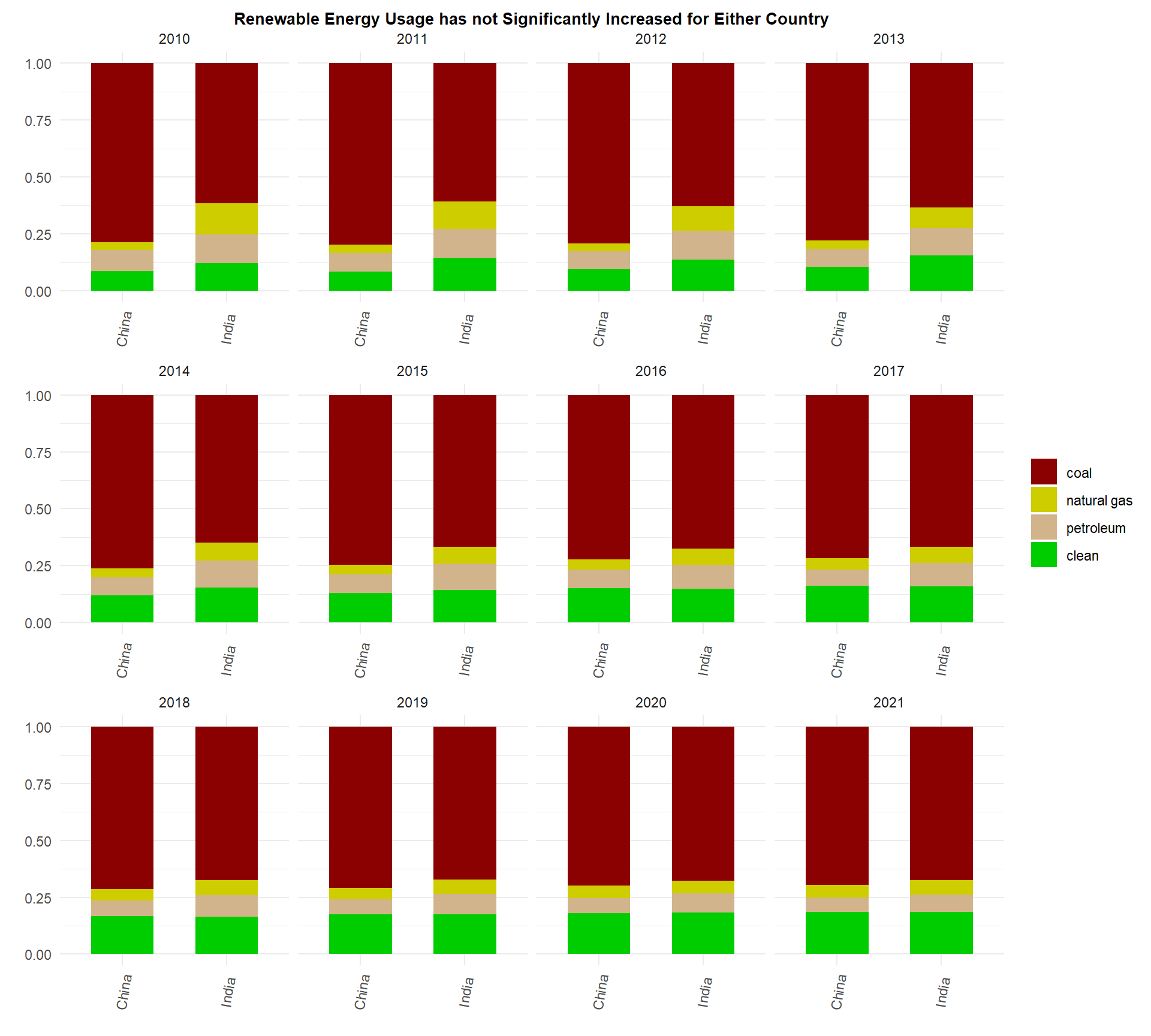
The outlook of energy production/consumption is also key to our discussion as it, quite literally, fuels economic growth. From the plot we see that since the year 2010, only a small fraction of both China and India’s energy production comes from clean energy sources such as nuclear energy and renewable sources like solar and wind energy. Moreover, both countries rely on coal as their primary energy source which according to the EPA and other environmental organizations is the biggest emitter of greenhouse gasses along with natural gasses. China has higher levels of coal usage and lower amounts of renewable energy than India, but there is a promising increase of renewable energy sources in recent years. As of 2021, almost 20% of both countries’ energy production are from clean energy sources such as nuclear or renewable energy. Thus, it is promising that these two countries are increasing their reliance on clean energy production instead of coal and natural gases. However, as the population of both countries grow (particularly India’s) it is inevitable that energy demands will significantly increase, and it remains to be seen if renewable energy sources can keep up.